
By Louie De Luna, Agnisys Chief Product Evangelist
The idea of an open-source CPU core was virtually unheard of ten years ago – let alone using it for commercial applications. The CPU core has been the most critical part of any computing system and thus, has been the most valuable and profitable. Over the years, companies like IBM®, Intel®, and ARM® have built their empires either from CPU core development or license distribution.
Fast forward to today, the entire computing industry is in the early stages of a new paradigm shift where the CPU would no longer be the central processing unit. Mainly driven by the exploding growth of data that we produce and consume as a global society, even the highly successful von Neumann architecture is becoming obsolete. Prediction, analytics, and machine learning training utilize big data, while real-time applications like IoT edge, geospatial systems, and autonomous vehicles make use of fast data.
As we prepare for the future, data will need to be at the center stage. The computing architecture would need to be data-centric rather than CPU-centric. The CPU would only be one of the types of hardware along with GPUs, FPGAs, custom accelerators, special-purpose CPUs, memory, and storage, all connected to an open-source interface and all are powered by an open-source Instruction Set Architecture (ISA). The ISA that is poised to be the key enabler for all of this is RISC-V. Ever since the group at UC Berkeley completed RISC-V and released it as open-source in 2014, the game started to change. In 2015, following the success of the Linux Foundation, organizations initiated the RISC-V Foundation, which now includes 325 member organizations. These members work together to ensure that the world's first open ISA becomes valuable for mass adoption. 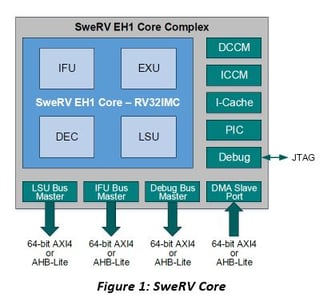
Western Digital Corporation (WDC), one of the founding leaders of the RISC-V Foundation (and also one of our customers), released a commercial-grade open-source CPU core based on RISC-V called SweRV™, a 32-bit CPU that supports RISC-V integer, compressed instruction, multiplication and division, and instruction-fetch fence and CSR instructions extensions. The core is a 9-stage, dual-issue, superscalar pipeline. SweRV delivers about 4.9 Coremark/MHz, in-between Intel Xeon™ E5 at ~5.5 Coremark/MHz and ARM Cortex™ A15 at ~4.7 Coremark/MHz.
The spec, design source code and testbench for SweRV are available on GitHub. If you plan to integrate SweRV into your commercial SoC, you'll need a more robust hardware verification approach since the testbench for commercial applications is quite limited. At a minimum, you would need the test scenarios and test environments for simulation, firmware tests, and board testing. For stimulus, typically you would need:
- UVM sequences for UVM-based simulation
- C-based sequences for firmware tests
- C-based sequences for hardware/board tests
One of the main challenges in creating the sequences is that multiple engineers with varying types of expertise would need to write them in the target language for simulation, firmware tests, and board testing, even though the sequence functionality is the same. And before they can even code the sequences, they must first understand the test spec which in itself requires a significant amount of time and effort.
In this blog, we will show how you can describe the sequences in pseudo-code only once, and use ISequenceSpec™ Sequence Generator to generate the sequences in the target language. To demonstrate this, we chose SweRV’s Programmable Interrupt Controller (PIC). The PIC core is responsible for evaluating all pending/enabled interrupt requests and picking the highest-priority request with the lowest interrupt source ID. Section 5.5 Theory of Operation of the SweRV specification describes the sequences for initialization and regular operation.
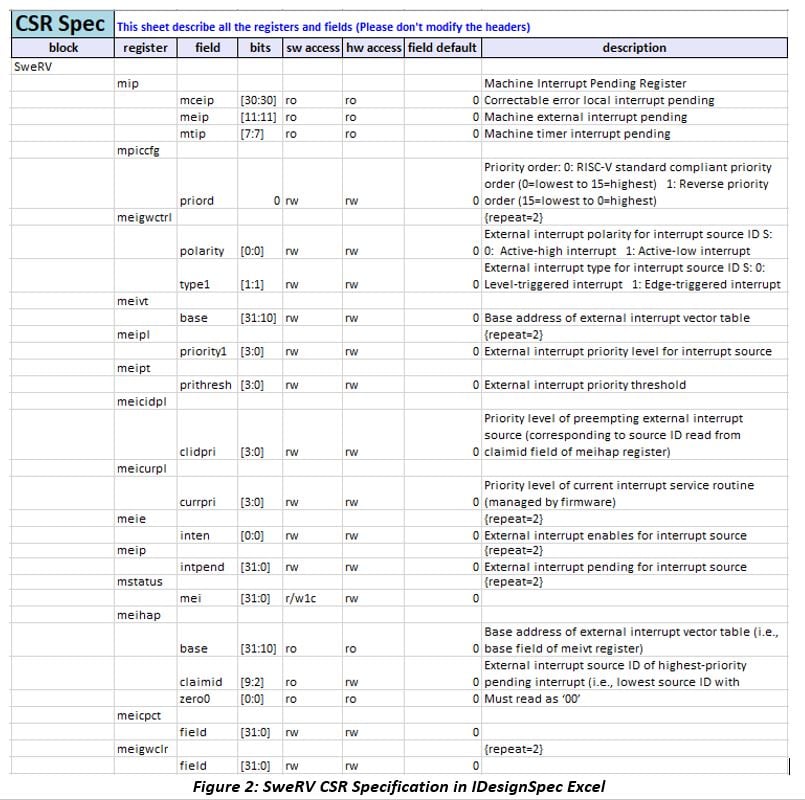
SweRV CSR Specification
Sequences mainly consist of various register reads/writes that are executed in series or in parallel. So first, we need to make sure that we have the SweRV Control Status Register (CSR) properly defined. Figure 2 shows the CSR definition in spreadsheet format using IDesignSpec™ Excel. SweRV has 14 unique registers which a few of which are simply repeated twice such as ‘meigwctrl’ and ‘meipl’ registers. The corresponding RTL, UVM register model, C Headers, and documentation can be easily generated from a single source using IDesignSpec. When the CSR is captured in this manner, you will be able to minimize SoC functional flaws caused by errors/changes in the specification.
PIC Core Initialization and Regular Operation Sequences
You can specify hierarchical sequences in pseudo-code using Python text, Word™ document style, or Excel™ spreadsheet environments. Language constructs such as ‘if-else’, ‘while’, and ‘for’ statements can be used, as well as ‘fork-join’ statements for concurrent sequences. Similarly, randomization and constraints for fields and variables are also supported. There are five main sections used for describing the sequences:
- IP – Specifies the absolute or relative path of the register map defined in IP-XACT, System RDL, RALF, document, or sheet in the same workbook. In the Description corresponding to the IP, the user can describe general description of the sequence. Properties used for the entire sequence can also be defined here.
- Arguments – Refers to the variables or expressions passed from the caller of a macro sequence (or function) into another macro sequence. The macro sequence accepts the argument and returns a sequence back to the calling sequence. Thus, it can be termed as two-way communication between the calling macro sequence and the called macro sequence.
- Constants – Users can specify various types of number formats (binary, decimal, hexadecimal, etc.) as the value of constants. Such values which won’t alter during the course of execution can be described here.
- Variables – Can be declared with value or without value, ISequenceSpec substitutes the body of the variable at each point where the variable is called at run time.
- Sequence Steps – Users can specify the steps that are needed to perform sequentially.
Figure 3 shows the initialization sequences for the PIC core captured in pseudo-code.
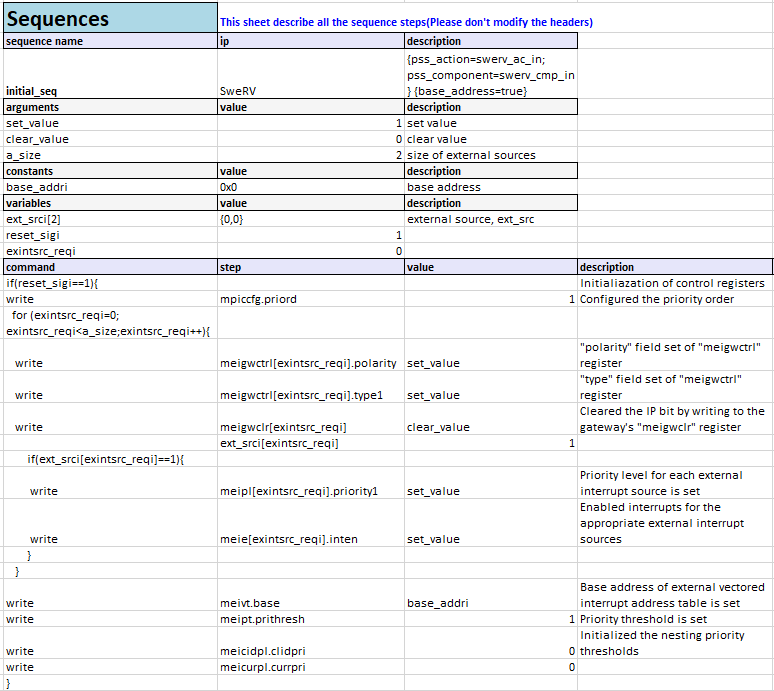
Figure 3: Sequences for Initialization of PIC core in ISequenceSpec Excel
Figure 4 shows the sequences for the regular operation of the PIC core in pseudo-code.
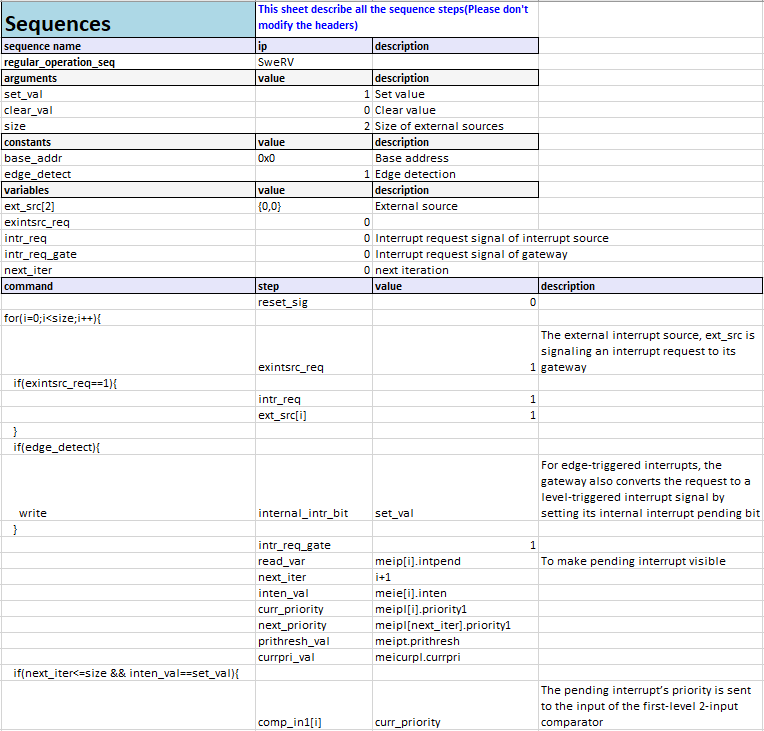
Figure 4: Sequences for Regular Operation of PIC core in ISequenceSpec Excel
During the creation of sequences, users may encounter syntax and semantic problems. To address this, ISequenceSpec is equipped with a smart syntax and semantic checker that validates the format and syntax within the specification. Once the validation is complete the user can generate the output sequences in the target language. In this example the following outputs are generated:
- UVM sequence – This is the sequence package that can be used for UVM-based simulation. We create sequence classes that are extended from ‘uvm_reg_sequence’ Arguments are handled here using ‘init´ function. Read/write transactions on registers occur via register model ‘rm’ inside the task body. If ‘max nesting’ is set to ‘1’ in ‘configure’ of the ‘UVM’ output, then the called sub-sequence is flattened in the top sequence. In case it is set to level ‘2’ then the called sequence class is created and then called. This concept applies to C output as well. The UVM directory includes two files:
- swerv_seq.uvm.sv – sequence file
- riscv_ip_pkg.uvm.sv – package file
- C sequence – This is the C sequence package that can be used for firmware tests. We create functions with a certain ‘return type’. This return type can be changed in the configuration settings. Here, we can do register and field writes through the default APIs that we provide (APIs are in the file with extension <seq_name>_iss.h). User can also read/write through their own APIs by adding templates in the configure section. Templates can also be added for UVM output if the user has any. The C directory includes four files:
- riscv_ip.h – header file
- swerv_seq_iss.c – sequence file
- swerv_seq_iss.h – API file
- riscv_ip_pkg_firmware.h – package file
- Platform sequence – For board testing, ISequenceSpec has a ‘Platform’ output where the user can specify the board to use for testing. The user can also specify the base address of the IP implemented in the board, APIs used for writing/reading the registers, pre-defined initialization, and clean-up functions. Based on the board type, the requisite libraries are automatically included in the generated C code. Once generated, the sequences are ready to run on the board. The platform directory includes two files:
- riscv_ip.h – header file
- swerv_seq_iss_platform.c – sequence file
NOTE: Feel free to contact us if you need the full package of input and output files mentioned in this blog.
The golden-spec methodology involves specifying sequences in a single source and enabling the code generator to retarget them in various languages. All sequences derive from a golden spec, and any changes to the sequences must occur in the spec rather than directly in the code. This would prevent discrepancies between sequence functionality used in simulation, firmware tests, and board testing.
Naturally, similar to the PIC core, there are various on-chip IPs in the SweRV core. Sequences for these IPs can also be specified using ISequenceSpec and the sequence code generated. As you adopt the SweRV core into your SoC you would also have off-chip IPs connected to the core through a system bus such as 64-bit AXI4 or AHB-Lite. These standard buses are supported by our tools such that the bus interface logic is also auto-generated along with the RTL and UVM register model.
The SweRV core is set to play a critical role in the mass adoption of RISC-V. WDC has committed to transitioning over 1 billion cores per year into RISC-V, and the SweRV core will be the first one to be integrated. The road towards mass adoption will be certainly long and bumpy, but with the contributions from companies such as WDC, the future looks bright, especially if the entire industry collaborates together and puts aside competitive nuances.
The world is producing an unbelievable amount of data at an ever-increasing rate, and by 2020 we should have about 40 trillion gigabytes of data of which 90% was only produced within the last 2 years. High-quality data, with its ability to be reused, replicated, and transferred at the speed of light, has the potential to become more valuable than oil. It can power numerous AI applications, simplifying our daily lives. Open-source interfaces and open-source CPU cores are now evolving to become more data-centric. In a way, we are witnessing the works of innovation as it turns and switches gears.
